Extraction Info from Data




Pandas and DataFrames
Pandas is a python library. Pandas will help you to explore, clean, and process your data. In pandas, a data table is called a DataFrame. We use to import the library using "import pandas as pd".
When looking at a data set, check to see what data needs to be cleaned. Examples include:
- Missing Data Points
- Invalid Data
- Inaccurate Data
Example below:
import pandas as pd
df = pd.read_json('files/grade.json')
print(df)
For example, the grade of the students were not unity.
import pandas as pd
import seaborn as sns
# Load the titanic dataset
titanic_data = sns.load_dataset('titanic')
print("Titanic Data")
print(titanic_data.columns) # titanic data set
print(titanic_data[['survived','pclass', 'sex', 'age', 'sibsp', 'parch', 'class', 'fare', 'embark_town']])
import pandas as pd
dataset = [
{
"name": "PRECIOUS ACHIUWA",
"team": "TOR",
"age": 23,
"height": 2.03,
},
{
"name": "STEVEN ADAMS",
"team": "MEM",
"age": 29,
"height": 2.11,
},
{
"name": "BAM ADEBAYO",
"team": "MIA",
"age": 25,
"height": 2.06,
},
{
"name": "OCHAI AGBAJI",
"team": "UTA",
"age": 22,
"height": 1.96,
}
]
df = pd.DataFrame(dataset)
print(df)
print("Oldest: " +str(df["age"].max()))
print("Youngest: " + str(df["age"].min()))
print("Tallest: " + str(df["height"].max()))
print("Shortest: " + str(df["height"].min()))
Quiz Reflection
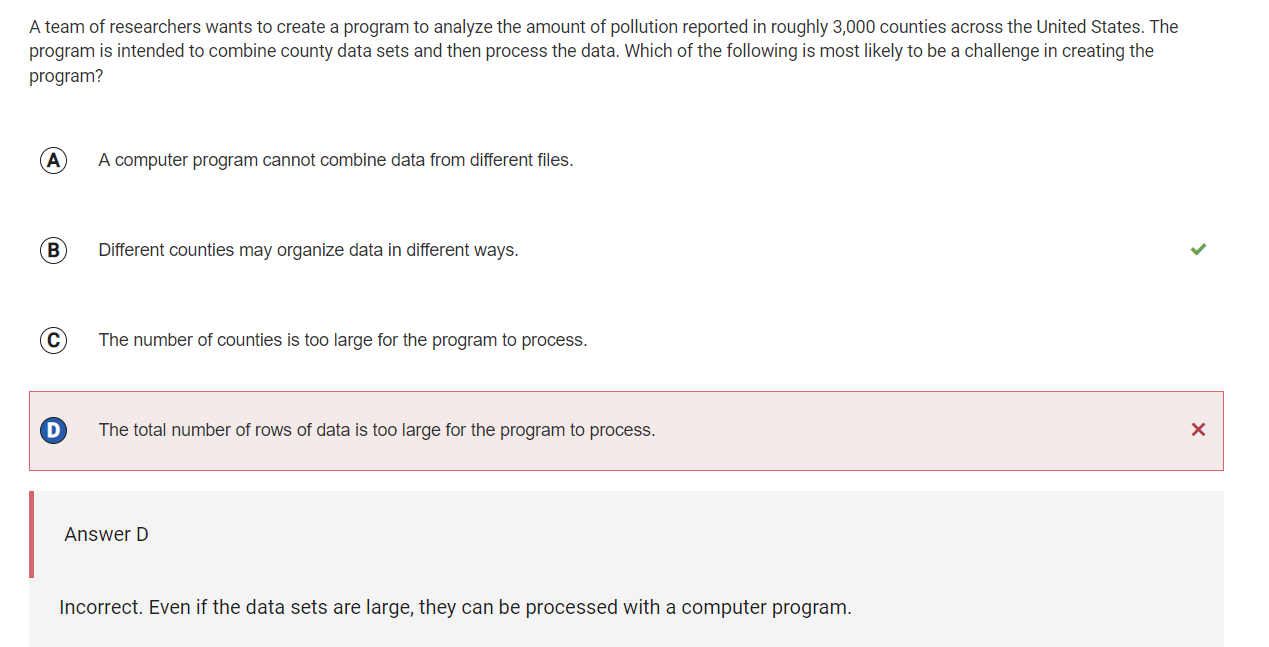
For the first wrong question, B is correct because it will be a challenge to clean the data from the different counties to make the data uniform.
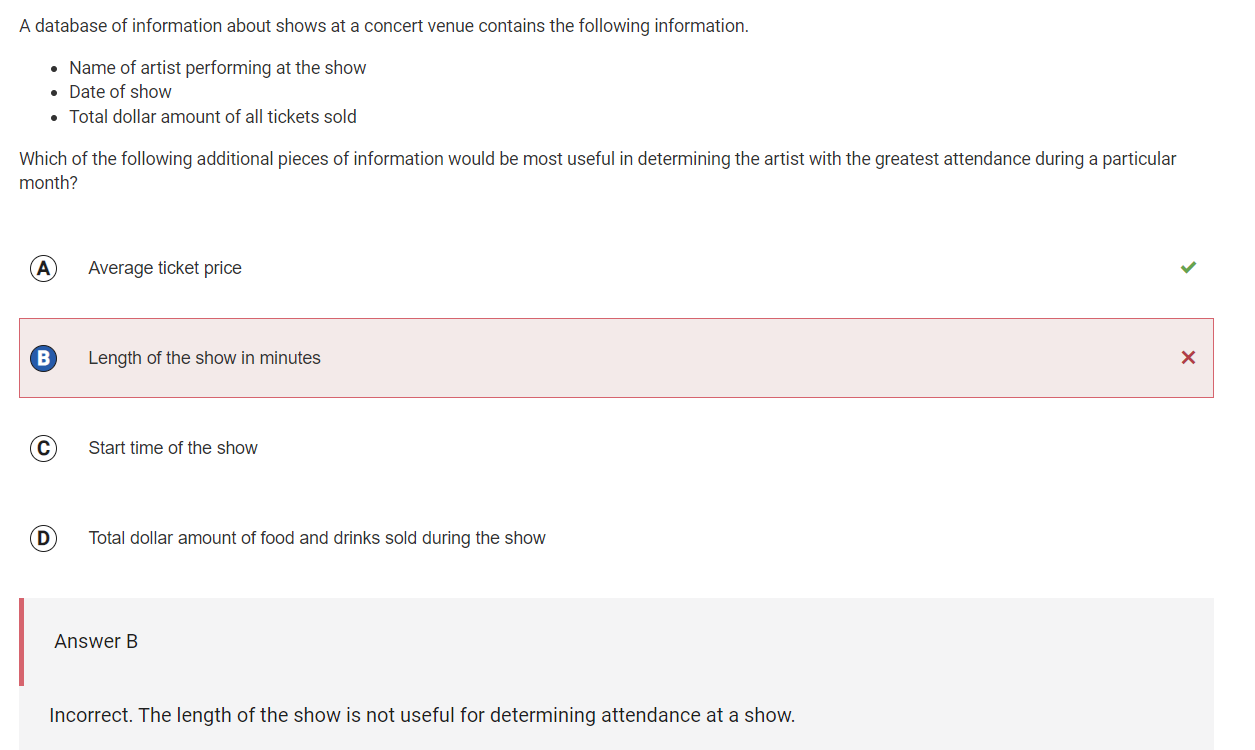
For the second wrong question, A is correct because the attendance for a particular show can be calculated dividing the total dollar amount of all tickets sold by the average ticket price.